


Project: Bellabeat
PROJECT BACKGROUND
Bellabeat manufactures smart health-tracking devices for women. Besides their traditional smart trackers, they also offer a wide range of technology products, such as a smart water bottle that tracks your water intake and an app in which women can receive specific health advice from a coach.
The problem
Bellabeat wants an overview of how users use their smart devices to guide their marketing strategy.
Data is spread across different data frames.
The goal
Collect insights to support marketing strategy based on provided dataset.
My role and responsibilities
This exercise was presented as the Capstone Project for Google’s Data Certification programme. I worked as a Data Analyst, from the preparation of the data to the presentation of Insights.
Tools used in this project
- R Studio (all the data analysis happened in R Studio)
- Photoshop (for treating some images)
- Google Slides
- The code can be found in GitHub ????????.

/* MENU */
- Business Task: Asking Questions
- Preparing the Data
- The Analysis Process
- The Results
- The Limitations and Next Steps
- What I Learned

1. Business Task: Asking questions
“Far better an approximate answer to the right question, which is often vague, than an exact answer to the wrong question, which can always be made precise.”
John Tukey
An excellent analysis starts with well-defined problem questions. From Bellabeat’s stakeholders, I received three main questions which should drive the analysis process:
- What are some trends in smart device usage?
- How could these trends apply to Bellabeat customers?
- How could these trends help influence Bellabeat’s marketing strategy?
After consideration, I decided to start by performing brief research on the latest developments and trends in the smart device industry. The summary can be seen in the image below.
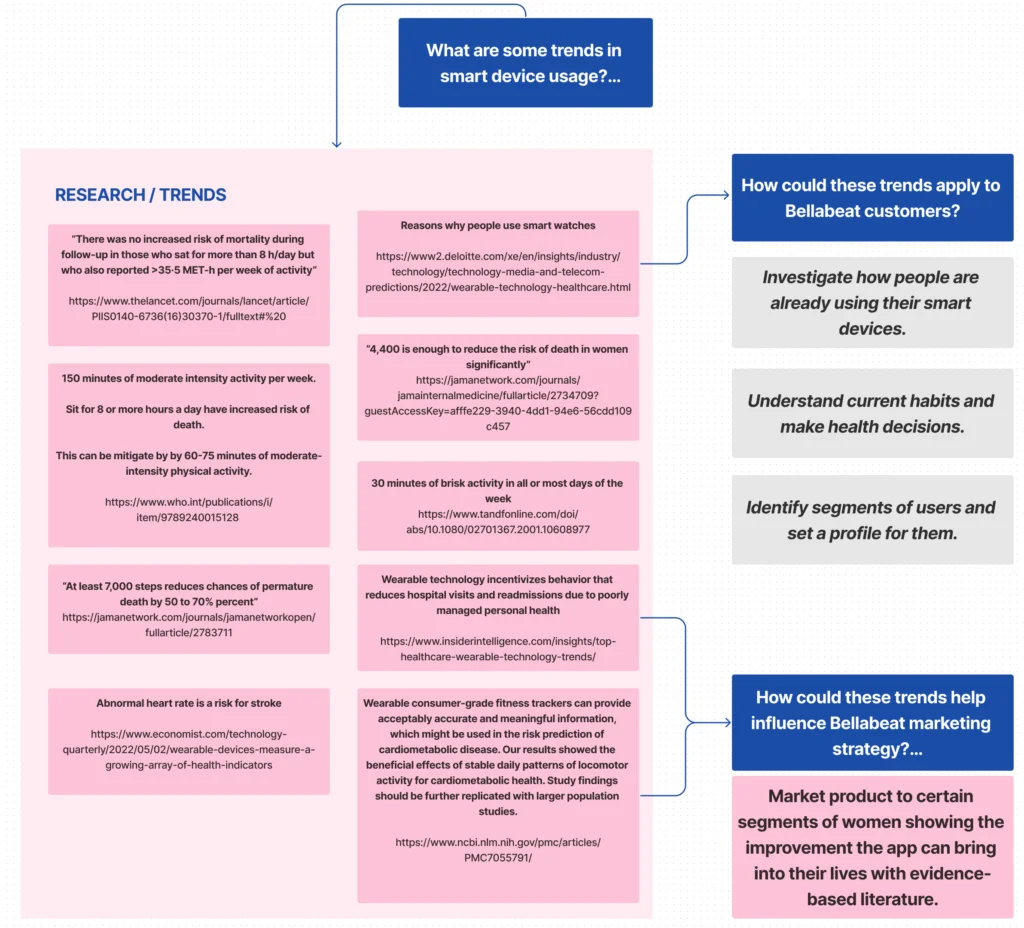
Next, I created a preliminary set with 3 groups of questions for my investigation. This set differs from the stakeholders as the questions listed here are specific enough to have answers collected by performing a series of steps (or scripts). But as within all projects in the digital sphere, this is not a static list but rather an incremental one. As I move on to understand my data, new questions could be added to the list.

2. Preparing the data
The next step was the preparation of the data. As it was my goal with this project to develop some skills in R, I decided to import all the data sets to R Studio and so make sense of what I had. By looking at the information this way, I created a model with all the tables and their respective fields. Furthermore, I had to verify some assumptions I had about the data (some tables looked like the merge of other ones).
Next, I decided on which tables were necessary for my analysis and moved on to clean the data. As I am giving recommendations based on the overview behaviour of users, I decided to use mainly daily values instead of the ones broken down by hour or minute. All the data preparation can be followed in detail in Kaggle.

3. The analysis process
The exploratory data analysis started with investigating the reasons why these users are using Bellabeat and the frequency of the use. Next, I explored possible segments in the data: based on their time wearing the devices, their risk of premature death and on their fitness level. Here I encountered an issue in the dataset that I could not pass by without consulting with the stakeholder: the number of sedentary minutes in some cases accounted for 1,440, meaning the user didn’t do any activity or slept. Therefore, I decided not to focus my analysis on variables marking activities minutes.
Moving on, I looked for patterns in the data (in terms of days of the week and segments), and finally, I applied several statistical tests to infer if differences in groups were due to statistically significant associations.
The analysis process is available in detail at Kaggle. In the end, I plotted 20 graphs, some of which were used for the presentation slides.
4. The results
In summary, I collected the following insights:
- Most of the data is recorded automatically. Only 3,4% of data is recorded manually by users.
- Users are using the trackers to record their activity automatically, followed by monitoring sleep and heart rate.
- Of the entire data set, only 3 people monitor everything.
- Most users of this sample (88%) use the smart watch with high frequency or more than 80% of the time (25-31 days).
- The majority of my sample has a low risk of premature death due to their average number of steps.
- The number of steps and calories is somehow constant among users.
- Users are not sleeping the recommended amount of 7 hours.
- The total number of steps is more constant for Loyal users when compared to Casual and Rare users. I see similar behaviour if I break down my users into groups with different risks of premature death. Users with a low risk of premature death perform on average more than 7,700 steps every day of the week. Users with a low risk of premature death spend more calories on average than the other groups, who do not even reach the minimum of 2200 calories/spent to maintain their weight.
- Again, the trend is similar for Loyalty groups: Loyal users consume more calories than the other two groups. Lastly, we can see that the number of minutes of sleep is somewhat constant throughout the week for individuals classified as loyal users. Casual users sleep more on Sundays. We do not have enough data for Rare users. Regarding premature death risk, users with a low risk of death sleep less than the other groups, however, the differences are not too big.
- There is a statistically significant monotonic relationship between Calories and Steps with moderate strength. This means that when the number of Calories increases, so does the number of steps.
- As for Sleep and Calories, although the relationship exists, it is considered weak. Additionally, Calories have a moderate association with Total Distance and Very Active Minutes, while Total Steps and Total Distance have a very strong association (which is not a surprise!)
- There is no statistically significant relationship between the segments proposed in this analysis (p < 0.05).
- Most users are considered loyal, with a low risk of premature death (19/33). We have, however, 5 users with a Medium risk and 5 with a High risk of premature death.
Naturally, the insights were summarised in a presentation:
5. Limitations and Next Steps

It is crucial to address the following limitations regarding this data set:
Bias due to sampling size: A sample size to infer general behaviour should be relatively larger regarding users and data collection time.
Unclarity on variables: It is not clear what some variables record, which could lead to misaligned with future analyses. It is recommended to create a document or additional metadata when providing the set. For example, it is unclear how values for Sleep Minutes and Sedentary Minutes overlap.
Moreover, for future analyses, it would be interesting to explore the behaviour of users in a more detailed aspect. It is also relevant to perform further research and try to segment users by the risk of stroke based on their heart rate.
6. What I learned
I learned a ton about R! Although we had a course during the Google Certification programme on R programming, it wasn’t quite enough to carry on this project. So I basically devoured this book before I put my hands (and brain) to work: R for Data Science.
Additional honourable mentions to: